iOS捷径 + github action 构建无压力记录工作流
为什么随时记录想法很重要
最近读到的公众号“李睿秋Lachel L先生说”的文章《我的思考工作流(2024年版)》中提到及时记录想法的重要性:
一个经常被人忽略,但又至关重要的做法是:及时把你的想法记下来。
我们每天会有超过6000个想法。哪怕这些想法只有1%是有用的,那也有60个。只要这60个能够有10%为我们所用,也能创造不菲的价值了。
但是,大多数想法都是转瞬即逝的 —— 它们往往存在于一瞬间的闪念里。可能是对阅读到的内容的联想,可能是对某件事项或任务的灵感,可能是对未来的一个计划……
它们持续的时间非常短,可能只有几秒钟,随即就被新的想法、新的信息所吸引注意力。
因此,维护一个能够及时记录想法的流程,就尤为重要。它只是一个最简单的步骤,但却是整个思考工作流的入口和第一环节。
我的痛点
对于“维护一个能够及时记录想法的流程,就尤为重要”的观点,我深以为然。一直以来我都通过logseq这款软件作为记录和初步整理自己思考的入口,但一直有几个困难让这个流程并不顺畅。
首先,多平台同步问题。我用iPhone,但工作电脑是PC机,iCloud在Windows上同步不便,同步时机和冲突问题导致跨系统同步体验差,经常需要手动处理。
因此,我使用git来同步logseq。但这引入了新问题。在移动端,每次操作前需从远程仓库拉取最新更新,记录后需提交并更新到远端仓库,以避免冲突。尽管iOS中的自动化可简化这些操作,但实际使用中常遇到异常,需要手动介入。
其次,logseq移动端操作不便,我希望找到更便捷、无压力的随时记录方案。
审视我的需求,我在想是否过于复杂化了。我在移动端的需求是随时记录,并同步信息至知识库。logseq只是打开知识库的工具而已。
最近读到一篇博客,介绍使用github action将本地笔记同步至github仓库,我立刻想到这可能解决我的问题。。
构建无压力记录的工作流
下面我就介绍我的工作流,有几个前提条件:
- 知识库在github托管
- iPhone(安卓的话应该会更加简单)
使用捷径随时记录
参考几位博主的做法,我改造了一个闪念胶囊捷径(见文后链接),实现以下功能:
- 选择“iOS的语音识别”、“文字输入”、“录音后调用openai whisper”任意一种方式完成记录
- 调用openai接口帮助我润色记录的内容
- 将润色后的记录写入名称为当前日期的备忘录

这样,我的记录是没有压力的,随时写下来,随时写入到备忘录中,像日记一样想要找哪一天的记录可以查看对应日期的备忘录。
自动同步至GitHub仓库
基础设置
可参考博客《利用 GitHub Action 和快捷指令解决 Logseq 最后一米问题》来实现同步至GitHub仓库的操作。但在实践中,我发现部分步骤已有变更,故需要作出相应修改。
在GitHub Action YAML文件中增加设置权限操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31name: Add to Journal
on:
workflow_dispatch:
inputs:
text:
description: Add a single item to Logseq journal
type: string
required: true
permissions: write-all # 新增设置权限步骤,以确保可以执行git push
jobs:
add_to_journal:
name: Add item to journal
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Add line to file and commit
run: |
filename="journals/$(date +'%Y_%m_%d').md"
echo "- ${{ github.event.inputs.text }}" >> $filename
git config --local user.email "[email protected]"
git config --local user.name "GitHub Action"
git config --local --unset-all "http.https://github.com/.extraheader"
git add $filename
git commit -m "Journal added by github action"
- name: Push changes
uses: ad-m/github-push-action@masterGitHub接口调用规范已更新
原文提到将头部的Authorization设置为
token {your_token}。根据新规范,头部认证应修改为Authorization: Bearer {token}。以下两个接口操作也需相应修改:获取workflow ID:
1
2
3
4curl --location 'https://api.github.com/repos/{owner}/{repo}/actions/workflows' \
--header 'Authorization: Bearer {token}' \
--header 'Accept: application/vnd.github+json' \
--header 'X-GitHub-Api-Version: 2022-11-28'推送更改:
1
2
3
4
5
6
7
8
9
10
11curl --location 'https://api.github.com/repos/{owner}/{repo}/actions/workflows/{workid}/dispatches' \
--header 'Accept: application/vnd.github+json' \
--header 'Authorization: Bearer {token}' \
--header 'X-GitHub-Api-Version: 2022-11-28' \
--header 'Content-Type: application/json' \
--data '{
"ref": "main",
"inputs": {
"text": "测试使用Github输入"
}
}'
iOS自动化定时推送
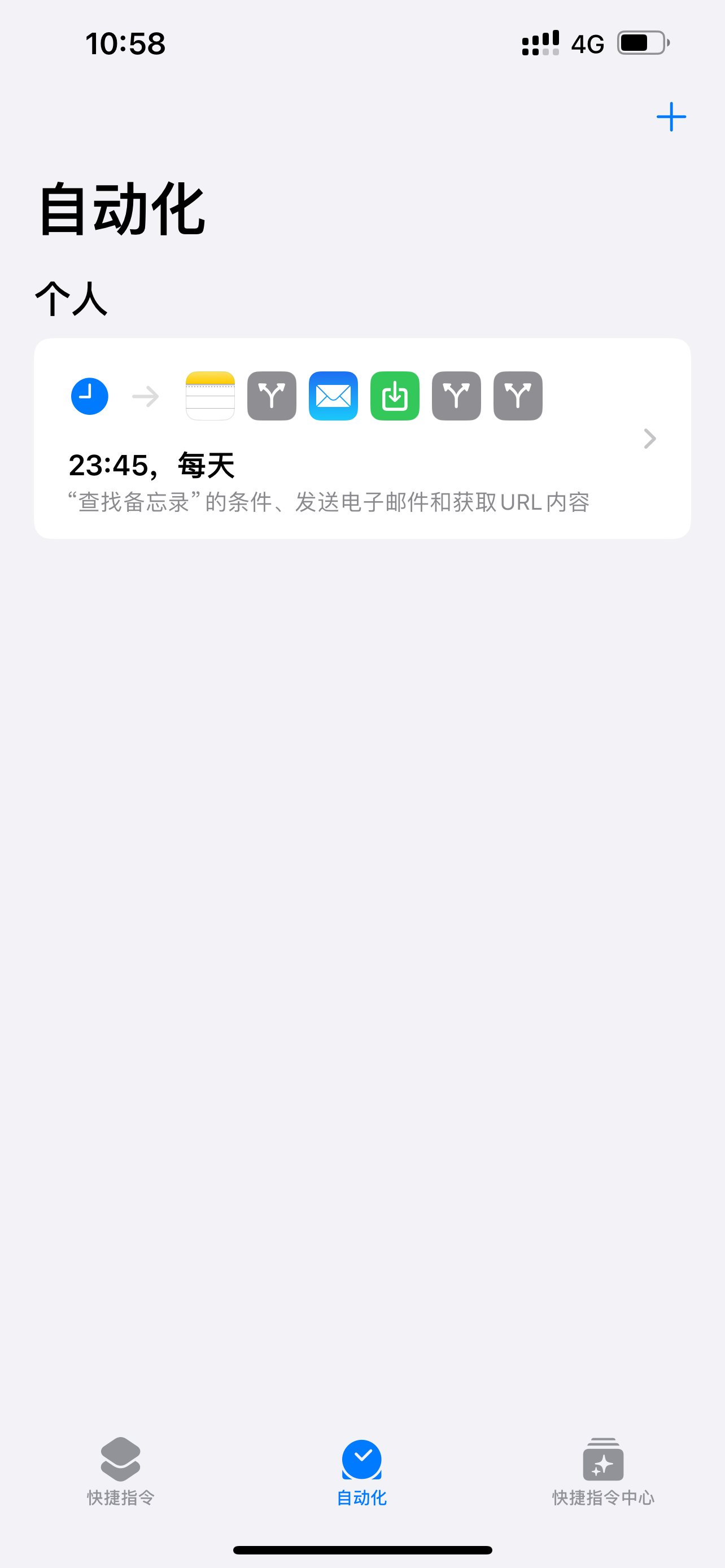
在iOS捷径菜单中创建一个自动化计划,设定每天23:45自动将记录的想法推送至GitHub仓库。
总结
这篇博文介绍了我利用iOS的“捷径”,“自动化”与github action实现了一个随时记录,定时同步到远程仓库的工作流。如果你也有和我相同的需求:
- 移动端只用来记录想法,日常在桌面端整理笔记、想法
- 多平台同步,但对实时性要求不高,能接受T+1同步
那么不妨试试我的方法。如果有问题,可以在评论区联系我。

 {:height 660, :width 764}
{:height 660, :width 764}